1) Vectors: The Fundamental Data Object
1.1 What is a vector?
A vector is a 1D array of numbers. You can think of it as:
- A list of features for one data point (e.g., height, weight, age).
- A point in space (2D, 3D, or higher dimensions).
- An arrow with direction and length (geometric view).
Notation: a vector is often written as 

1.2 Geometric picture (vector as an arrow)
In 2D, a vector 

1.3 Norm (length) of a vector
The norm measures vector length. The most common is the Euclidean (L2) norm:

1.4 Unit vectors
A unit vector has length 1: 
Any non-zero vector

In 2D, unit vectors can be parameterized by an angle 

1.5 Scalar multiplication and vector addition
- Scalar multiplication:
stretches (or shrinks) the vector. If
, it also flips direction.
- Vector addition:
adds component-wise and corresponds to “tip-to-tail” addition geometrically.
1.6 Inner product (dot product)
The inner product between vectors 

Geometrically, it connects to the angle

1.7 Projection and orthogonality
If 

The projected vector is:

Two vectors are orthogonal (perpendicular) if their inner product is zero:

2) Vector Spaces, Span, Linear Independence, and Bases
2.1 Vector space (big idea)
A vector space is a set of vectors where you can add vectors and scale them, and you stay inside the set.
For data work, 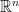

2.2 Span
A set of vectors 

2.3 Linear independence
Vectors are linearly independent if the only way to make:
is by using 
Intuition: none of the vectors is “redundant” (no vector can be built from the others).

2.4 Basis and standard basis
A basis is a set of vectors that:
- Spans the space
- Is linearly independent
The standard basis for

3) Matrices: Linear Transformations and Data Tables
3.1 What is a matrix?
A matrix is a 2D array of values. We write 



Higher-dimensional arrays are often called tensors.
3.2 Basic operations
- Addition/subtraction: elementwise (only if same shape).
- Transpose:
swaps rows and columns.
- Multiplication: defined when the number of columns of
.
If 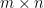
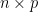



[ rows=m ] [ rows=n ] [ rows=m ]
[ cols=n ] [ cols=p ] [ cols=p ]
Requirement: inner dimensions match (n)
3.3 Key properties
- Associative:
- Distributive:
- Not commutative (usually):

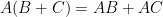

3.4 Special matrices
- Square:
- Diagonal: non-zeros only on diagonal
- Identity:
, diagonal of 1s
- Inverse:
such that
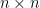
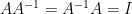
A matrix is invertible iff its determinant is non-zero:

3.5 Orthogonal matrices
An orthogonal matrix is a square matrix whose columns are unit vectors and mutually orthogonal.
It satisfies:
and therefore:


Intuition: orthogonal matrices represent rotations (and reflections). They preserve lengths and angles.
3.6 Matrices as linear transformations
A matrix 
- Diagonal matrices: scaling/stretching along axes
- Orthogonal matrices: rotation (or reflection)
- General matrices: combinations of rotation + scaling (and possibly shear)
4) Eigenvalues and Eigenvectors: Directions That Don’t Change (Much)
4.1 The core idea
When a matrix transforms space, most vectors change direction.
But some special vectors keep their direction (they may flip sign) and only get scaled.
Those are eigenvectors.
Definition: 


4.2 How to compute eigenvalues
Start with:
Rearrange:

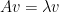
For a non-zero 

Solving this equation gives eigenvalues
4.3 Real vs complex eigenvalues (and “no real eigenvectors”)
Some transformations (like a pure rotation in 2D by a non-180° angle) do not have real eigenvectors.
In that case, eigenvalues/eigenvectors exist in the complex numbers (involving 
For many data applications, we often work with matrices (like symmetric covariance matrices) that guarantee real eigenvalues.
5) Eigendecomposition and Diagonalization
5.1 Eigendecomposition
If a matrix has enough eigenvectors to form a basis, it can be decomposed as:
where:

is a matrix whose columns are eigenvectors
is a diagonal matrix of eigenvalues
5.2 Symmetric matrices (very important in data)
If 
eigenvectors can be chosen orthonormal, so 

This shows a clean geometric story: rotate into the eigenvector coordinate system, scale by eigenvalues, rotate back.
6) Singular Value Decomposition (SVD): The Workhorse of Data Science
6.1 The decomposition
Any matrix
where:

: left singular vectors (orthonormal)
: right singular vectors (orthonormal)
: diagonal matrix of singular values (nonnegative)
6.2 Connection to eigenvectors
Singular vectors relate to eigenvectors of:


The singular values are square roots of eigenvalues of these matrices:

6.3 Geometric meaning: rotate → scale → rotate
Rotate input space
Scale along axes
Rotate output space
Why SVD matters: it powers dimensionality reduction (PCA), noise filtering, compression, recommendations, and more.
7) Data & Measurement: How Linear Algebra Represents the Real World
7.1 Entities and attributes
In data:
- Entity = an object/record/instance (e.g., a student, a document, a transaction)
- Attribute = a property/feature/variable (e.g., GPA, word count, price)
7.2 Discrete vs continuous attributes
- Discrete: finite/countable (zip code, words, categories)
- Continuous: real-valued measurements (temperature, height, time)
7.3 Tabular data as a matrix
A dataset is often a matrix 
- Rows = entities
- Columns = attributes
Example: if you have 10,000 students and 20 features each, then 
7.4 Document data (term vectors)
A document can be converted into a term vector (bag-of-words): each dimension counts how many times a word appears.
Then documents become vectors, and a collection of documents becomes a matrix.
7.5 Transaction data
Each transaction is a set of items (e.g., products bought together). You can convert this into a binary matrix:
- Row = transaction
- Column = product
- Entry = 1 if product is present, else 0
8) Distance Measures: Quantifying “Closeness” Between Data Points
8.1 Points as vectors in Euclidean space
Once you represent entities as vectors, you can measure how similar/different they are by using a distance function.
In geometry terms, each data point is a point in
8.2 What makes a distance a “metric”?
A true metric distance 
- Positivity:
, and
iff
- Symmetry:
- Triangle inequality:



8.3 Manhattan (L1) distance

Intuition: like navigating city blocks (e.g., NYC streets), moving along axes only.
8.4 Euclidean (L2) distance

Intuition: straight-line distance “as the crow flies.”
8.5 Weighted Euclidean distance
If some features matter more than others, use weights:

Larger 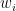
9) Standardization: Fixing the “Units Problem”
Distances can be misleading when features have different scales (e.g., “income” in dollars vs “age” in years).
A common fix is standardization (z-scoring):
For feature
where 


After standardizing, each feature has mean 0 and standard deviation 1, so no single feature dominates distances just because it has big numeric units.
10) Correlation Between Variables and Mahalanobis Distance
10.1 Why Euclidean distance can fail with correlated features
If two attributes are strongly correlated (e.g., “height in inches” and “height in centimeters” or related biology measurements),
Euclidean distance effectively counts the same underlying variation multiple times.
Also, data may be stretched more in one direction than another.
10.2 Mahalanobis distance
Mahalanobis distance accounts for feature scaling and correlation using the covariance matrix 

Intuition: it measures distance after “whitening” the data—transforming it so correlated directions are handled properly and the cloud becomes more spherical.
In many statistical and ML settings (anomaly detection, multivariate outlier scoring), Mahalanobis distance is a better fit than plain Euclidean distance.
11) Distance for Binary Data: Matching, Hamming, and Jaccard
For binary vectors (0/1), it helps to count how two vectors match:
: count of positions where both are 1
: count where first is 1 and second is 0
: count where first is 0 and second is 1
: count where both are 0
11.1 Matching distance
A basic idea is to measure (dis)agreement over all positions. Variants exist depending on whether you treat 0-0 matches as meaningful.
11.2 Hamming distance
Hamming distance counts how many positions differ:

This is often the simplest and most widely used for fixed-length binary strings.
11.3 Jaccard distance
For sparse binary data (like “did the user click this item?”), shared zeros are usually not informative.
Jaccard similarity focuses on “1” matches:

Then Jaccard distance is:

12) Summary: How the Pieces Fit Together
- Vectors represent individual data points (features for an entity).
- Matrices represent datasets and linear transformations.
- Eigenvectors/eigenvalues identify special directions that scale under transformation.
- SVD generalizes this idea for any matrix and is foundational for dimensionality reduction and structure discovery.
- Distances quantify similarity; choosing the right one depends on data type and geometry.
- Standardization and Mahalanobis handle scale and correlation, which matter in real datasets.